Recon
Recon Template is used to reconcile data between two datasets from any two data sources. It performs a row-by-row and column-by-column comparison to identify discrepancies.
To perform reconciliation, a Unique Identifier is required. This can be either a single column or a combination of columns that uniquely distinguishes each row. It serves as the key for evaluating checks on the other columns.
Use Cases
- Data Comparison (File vs. Database): When files are uploaded into a database, the Recon Template can identify data issues between the file and the resulting database records.
- ETL Pipeline: In an ETL pipeline, data flows through multiple layers. The Recon Template can reconcile data across different stages, taking ETL transformations into account.
- Migration Process: One of the biggest challenges during data migration is data loss or unintended changes. A Recon Rule can detect discrepancies introduced during the migration.
- Schema Comparison: Metadata validation to compare table names, column names, and data types between two schemas using information schema tables.
Sorting
Sorting is a critical component of the reconciliation rule. Before iceDQ begins comparing data, it assumes that both datasets are sorted in exactly the same sequence. For example, a customer table from two different layers of an ETL pipeline can be sorted using the customerID column (acting as a unique identifier) to ensure accurate comparison between the datasets. To sort the data correctly, follow these guidelines:
- Data type consistency: The data type of the unique column in the source dataset must match the corresponding column in the target dataset.
- Sorting order: If the unique identifier is composed of multiple columns, the sorting order must be identical in both datasets.
- Sorting mechanism awareness: Different databases and file systems may sort data differently. Even databases of the same type can behave inconsistently. To avoid false discrepancies, it is essential to apply the same sorting logic to both datasets.
Sorting Options
There are three ways to sort datasets in iceDQ:
- Using ORDER BY in SQL Query: The simplest method. Sorting is handled directly by the database using an ORDER BY clause.
- Append ORDER BY Automatically: When enabled, iceDQ appends the ORDER BY clause at runtime using the selected unique identifier columns. The sorting sequence matches the order in which columns are linked in the Diff Join tab.
- Deferred Sort: In this approach, iceDQ retrieves the data from the database and performs the sorting internally using its own logic. This is the most reliable method, as the same sorting principle is applied consistently across all datasets, regardless of the database type.
Components
There are seven (7) different components in a Recon Rule:
- Overview: To provide rule related metadata.
- Source Dataset: To provide source connection details required to fetch the dataset.
- Target Dataset: To provide target connection details required to fetch the dataset.
- Diff Join: To provide a unique Identifier between source and target datasets.
- Checks: To provide the conditions for testing the datasets.
- Exception Report: To provide the conditions for viewing and evaluating data mismatches.
- Summary: To provide variables that are attached to rule execution instance event.
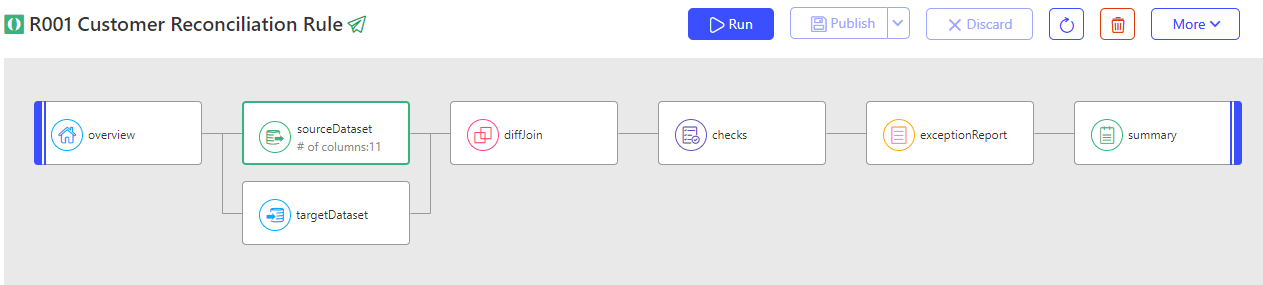
Following section describes the various fields of each component in detail.
Overview
This component allows users to define rules and configure advanced options for parameterization. Below are the details for the fields included in the rule definition:
| Field | Description | Purpose |
|---|---|---|
| Rule Name (Mandatory) | The unique name of the rule within a folder. It should be descriptive enough to help users quickly identify and understand the purpose of the rule. | Serves as the primary identifier for the rule. Ensures clarity and uniqueness within the folder structure. |
| Rule Code (Optional) | An alphanumeric shorthand or technical identifier for the rule. This field is optional but highly useful for efficient management and organization of rules. | Helps users search, filter, or differentiate between similar rules. Provides a compact reference for integrations, automation, or workflows. |
| Description (Optional) | A concise explanation of the rule. This field offers additional technical or business context to enhance understanding. | Clarifies the rule's intent or scope for users. Assists in onboarding new team members or providing documentation for audits. |
| Purpose (Optional) | A short summary describing the purpose or intended outcome of the rule. This field provides context for why the rule was created. | Highlights the business or technical objective of the rule. Helps users understand its significance and expected impact. |
| Criticality (Mandatory) | The Criticality field indicates the severity level of an issue. This is a mandatory field that helps categorize and prioritize errors based on their impact. The field provides the following options: Warning (Default): The issue should be reviewed but does not require immediate action. Critical: The issue needs to be resolved promptly; however, testing can continue despite its presence. Blocker: The issue must be resolved before testing can proceed, as it prevents further progress. | Ensures a clear understanding of the issue's severity, enabling teams to prioritize effectively and maintain workflow efficiency. |
Advance Settings
| Field | Description | Purpose |
|---|---|---|
| Parameter (Optional) | This field specifies the default parameter file associated with the rule. | Enables parameterization of the rule by referencing keys in the parameter file in SQL, checks, etc. |
Source Dataset
This section allows users to configure the source settings to extract data for processing. The following fields and options are available:
- Connection Type: This field allows users to select the type of data source (application, database, file ...) they want to connect to. Selecting the appropriate connection type ensures that only relevant connections are displayed for further selection.
- Connection: This field displays a list of connections available for the selected connection type. Once selected a user can:
- Test the connection using the ✔️ Checkmark Icon.
- Edit the connection details using the ✏️ Edit Icon.
- Refresh the list of connections using the 🔄 Refresh Icon.
- Methods for reading data from the data source
- Default: This option allows users to browse and select the required Schema and Table/View from the chosen connection. It is Ideal for users who prefer navigating schemas and tables visually without writing SQL.
- SQL: This option allows users to manually input custom SQL queries to retrieve specific data from the selected connection.It provides flexibility for advanced users to query data directly, offering precise control over the data extraction process.
- Preview Data: Clicking the Preview Data button allows users to view a sample of the data retrieved based on the selected table (Default) or SQL query.
Target Dataset
This section allows users to configure the target settings to extract data for processing. The following fields and options are available:
- Connection Type: This field allows users to select the type of data source (application, database, file ...) they want to connect to. Selecting the appropriate connection type ensures that only relevant connections are displayed for further selection.
- Connection: This field displays a list of connections available for the selected connection type. Once selected a user can:
- Test the connection using the ✔️ Checkmark Icon.
- Edit the connection details using the ✏️ Edit Icon.
- Refresh the list of connections using the 🔄 Refresh Icon.
- Methods for reading data from the data source
- Default: This option allows users to browse and select the required Schema and Table/View from the chosen connection. It is Ideal for users who prefer navigating schemas and tables visually without writing SQL.
- SQL: This option allows users to manually input custom SQL queries to retrieve specific data from the selected connection.It provides flexibility for advanced users to query data directly, offering precise control over the data extraction process.
- Preview Data: Clicking the Preview Data button allows users to view a sample of the data retrieved based on the selected table (Default) or SQL query.
Diff Join
The Diff Join component is used to define the Unique Identifier, along with its equivalent columns in the source and target datasets. In this tab, the user can view the columns from both datasets side by side. The simplest way to link matching columns is to click on a column from the source dataset and then click on the corresponding column in the target dataset. Repeat this process for all columns that form the unique identifier.
The order in which the user connects the columns determines the sorting sequence used during data comparison.
This component offers several additional options:
A. Connect – Provides two ways to automatically map columns between datasets:
-
Automap by Column Name: Automatically links columns with matching names between the source and target datasets.
-
Automap by Column Position: Links columns based on their position in the dataset. For example, the first column in the source will be linked with the first column in the target, the second with the second, and so on.
B. Add All as Checks – Automatically creates expressions for all linked columns.
- The expressions will follow this example format: S.[CustomerKey] == T.[CustomerKey]
C. Disconnect All – Removes all column links that have been created.
Checks
Checks are used to validate transformations, conversions, calculations, or any other test conditions involving two or more attributes from the source and target datasets. For a reconciliation rule, the engine evaluates Checks only for records (or rows) that are present in both the source and target datasets.
A complete list of Checks can be found here.
iceDQ supports the Groovy expression language for writing test conditions in Custom Check. You can use any Groovy, Java, or user-defined functions when writing these expressions.
Result Type
This is a pre-defined and configured type of check available in a Recon Rule. The engine will identify data issues based on the configured result type. The following are the options available in this check.
| Result Type | Description | Note |
|---|---|---|
| A minus B (A-B) | Only present in Source | This identifies all rows missing from target as failures. |
| B minus A (B-A) | Only present in Target | This identifies all rows not present in source as failures. |
| A intersect B (AnB) | Present in Source & Target | This identifies the matching rows between source & target as failures. |
| Expression (Xp) | Evaluate Checks | This identifies all the matching rows for which Checks are evaluating to false. |
Exception Report
This component is for the configuration of exception report display, storage, and export formats. Below are the different properties available in this component.
| Property | Description | Note |
|---|---|---|
| Export File Format | Specifies the default export format. Options include Excel or CSV. | |
| Store Failure & Errors Only | When enabled, only failed records are stored in the report. | This property is enabled by default. |
| Store Exported File Only | Deletes the raw exception report and retains only the exported file. | |
| Show Download Exception URL | Displays a download link for the exception report. | |
| Store Only # Rows | Limits the number of records stored in the report to the specified count. |
Summary
Users can configure result in override as well as attach custom variables to the Rule execution event.
Exit Code
The exit code of a Rule execution indicates whether the Rule succeeded, failed, or encountered an error. It represents the total number of common rows where one or more checks failed (evaluated to false) or where data issues were identified. It also includes source records missing from the target, and target records missing from the source, depending on the selected result type.
| Exit Code | Status | Note |
|---|---|---|
| == 0 | Success | This indicates that the rules executed were successful with all records. In this case, the source and target count match. |
| > 0 | Failure (Warning/ Critical/ Blocker) | This indicates that the rules executed failed with few or all records. In this case, the source and target count do not match. The positive number is an absolute difference between the count of source and target tables. |
| < 0 | Error | This indicates that the rule itself encountered an error during execution. Every negative Exit Code code has its own significance. In case of error, revisit the rule, input records or check the product health to figure out the issue. Or, contact iceDQ Support. |
| -38 | Error | The Check evaluated to FALSE but the difference of Source & Target is 0. |
When the Check evaluates to FALSE and difference is 0 the engine sets the Exit Code to -38 to prevent a False Positive result.
Below is the cheat sheet of how the Exit Code changes based on the selected Result Type.
| A minus B | B minus A | A intersect B | Expression | Exit Code |
|---|---|---|---|---|
| Yes | The engine identifies total number of rows present only in source as data failures and the same becomes exit code. | |||
| Yes | The engine identifies total number of rows present only in target as data failures and the same becomes exit code. | |||
| Yes | The engine identifies the total number of rows present in both source and target as data failures and the same becomes exit code (common rows). | |||
| Yes | All the rows which are present on both sides, but whose expressions are evaluating to false or error are identified as data failures. | |||
| Yes | Yes | The sum of total number of rows present only in source and total number of rows present only in target is the exit code. | ||
| Yes | Yes | The sum of total number of rows present only in source and total number of rows where expression is evaluating to false/ error is the exit code. | ||
| Yes | Yes | The sum of total number of rows present only in target and total number of rows where expression is evaluating to false/ error is the exit code. | ||
| Yes | Yes | Yes | The sum of total number of rows present only in source, target and total number of rows where expression is evaluating to false/ error is the exit code. |
Scenarios
Following scenarios will help you understand how the Exit Code of a Recon Rule changes based on selected Result Type.
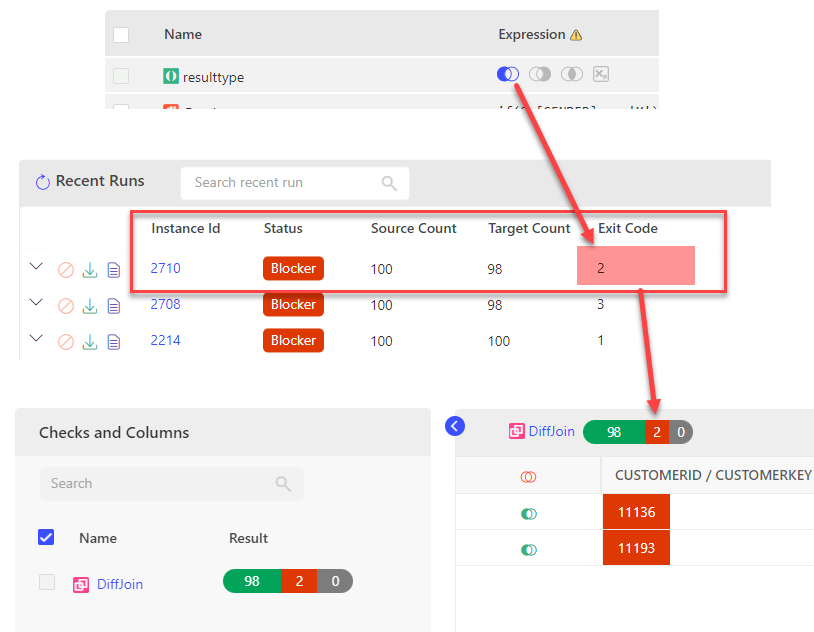
Scenario #1
In this example for selected Result A minus B (A-B) the Exit Code is 2 as the engine identifies 2 rows in source that are not in present in target as failures.
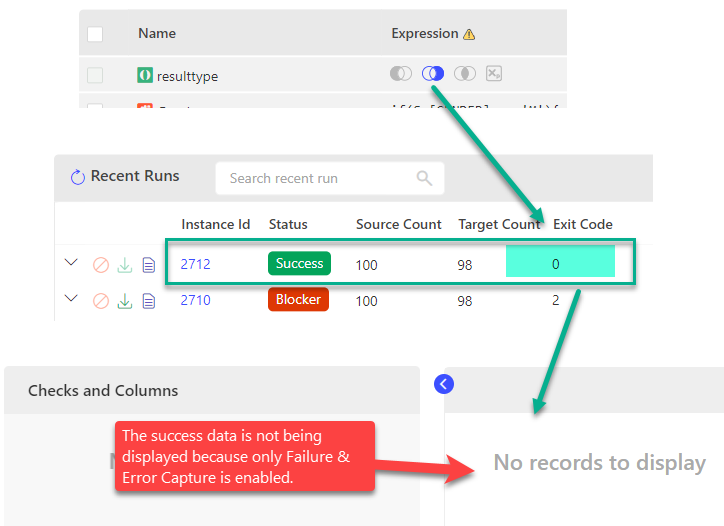
Scenario #2
In this example for selected Result B minus A (B-A) the Exit Code is 0 as the engine verifies that all rows from target are present in source.
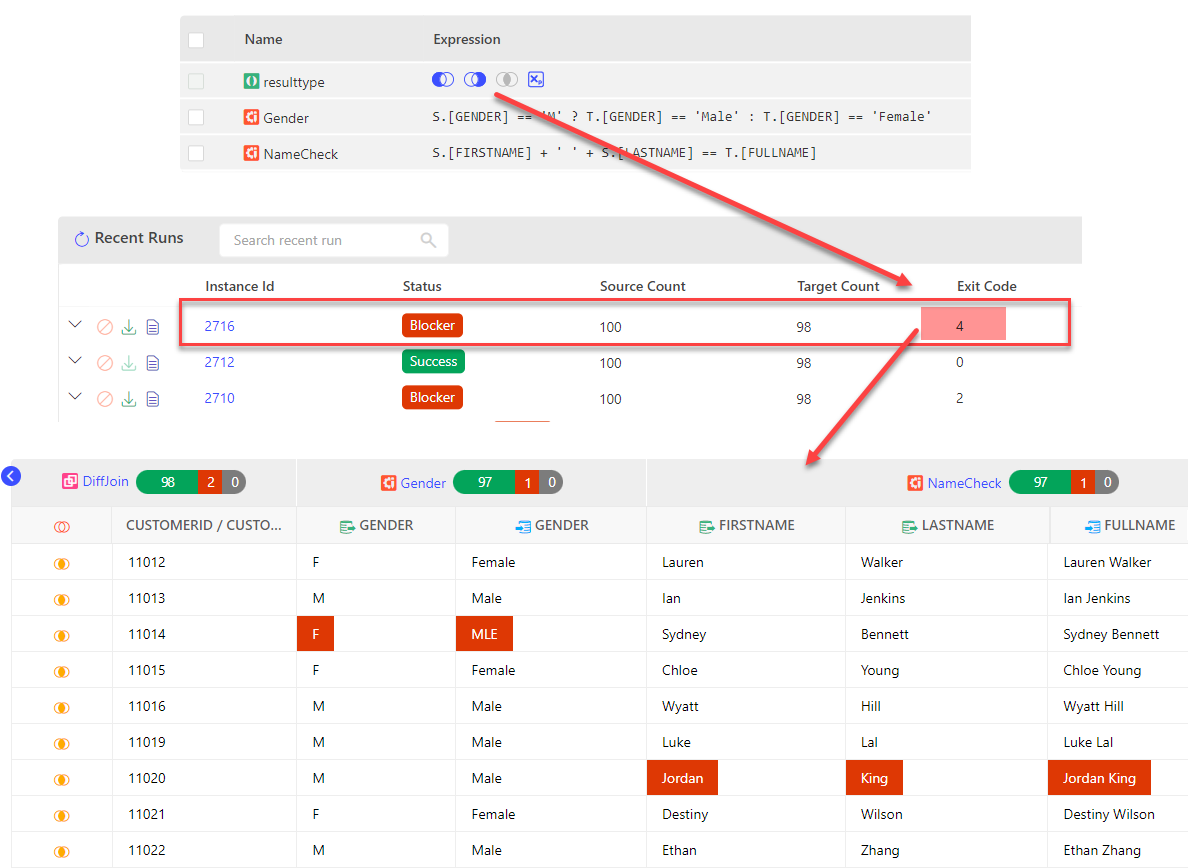
Scenario #3
In this example, for selected Result Type A minus B (A-B), B minus A (B-A) and Expression (Xp), the Exit Code is 4 as the engine identifies 2 rows that are only present in source, and 2 rows that are present in both source & target but their checks are evaluating to false.
How To: Create a Recon Rule
This video demonstrates how to create a recon rule using customer data.
Considerations
- Only use Underscore (_) and Hyphens (-) special characters are allowed in Rule Name
- Use column alias for SQL functions in SELECT
- Use Stop at Error & Store Failures Only for high volume data
- Ensure class of datatype for Diff Join columns is same
- Use append order by property to override sort order